Image via Wikipedia
 Differences between Search Engines
Differences between Search Engines

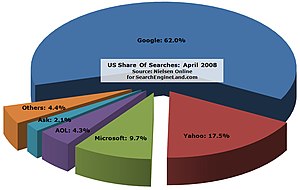
A search engine is a web application developed to hunt for specific keywords and group them according to relevance; search engines such as Google, Yahoo, and Microsoft are the most popular. Search engines are used by end-users to at least accomplish a specific research purpose or find information that will fulfill their web queries (i.e., what is a search engine?).
How search engines get the data? The first step is for search engines is to hunt for information through an automated process known as spidering. These spiders are commonly called bots, robots, or web-crawlers that are complex computer algorithms such as Googlebot that will continuously patrol the internet and fetch new information to be stored onto web-servers.
 Not all spiders are equally intelligent, but they all have one common purpose: (1) they crawl and collect website content; (2) they determine a websites location; (3) they determine the popularity of the website; (4) they record the characteristics of website; and (5) they rank the websites.
Not all spiders are equally intelligent, but they all have one common purpose: (1) they crawl and collect website content; (2) they determine a websites location; (3) they determine the popularity of the website; (4) they record the characteristics of website; and (5) they rank the websites.
A website has a specific architectural structure for holding information and the majority will have the following information in which a web-crawler will collect and store for its purposes (1) (not all inclusive):
| Title tag | Textual content (body) | JavaScript/CSS externalized |
| Meta tag | Alt attributes on all images | IP address |
| Meta keywords tag | Qualified links | File types / Image names |
| Heading tag(s) | Site map | Contact information |
| Strong/bold tags | Text navigation | Web analytics |
In the second step, search engines have to index the data it has collected in order to make it usable and retrievable. Indexing is the process of taking the spider's raw data and categorizing it, removing duplicate information, and generally organizing it all into an accessible structure – that is, a directory and sub-directory of folders and files with referential integrity; it's the same concept used in managing data of Relational Database Management Systems (RDMS).
Finally, for each web query by an end-user, the search engine applies an algorithm that evaluates many parametric and non-parametric criteria of a website that will generate an intelligent decision of which listings to display and in what order. These algorithms are computations that involve mathematics such as Statistics, Bayesian Networks, and Clustering in order to produce a particular web query outcome and collectively, these mathematical algorithms are known as, Data-Mining Techniques.
(1) "How Google Works - Google Guide," http://www.googleguide.com/google_works.html.
